

Engineering teams are rapidly adopting Generative AI. New challenges arise beyond the traditional software development lifecycle. To escape PoC purgatory, we must follow the Scientific Approach.
In this article we explore how and why the diffusion of generative tasks based on LLMs is affecting the software development lifecycle. We specifically cover the issues raising while moving from a Proof of Concept to a refined product. The main takeaway is a framework specific to these use cases, namely Evaluation Driven Development, along with concrete examples for implementing it in your project and team.
Generally speaking, the traditional software development lifecycle could be simplified as follows:
After decades of software development, we now roughly apply solution patterns to well-known problems with some degree of tailored approaches based on specific use cases. What is largely done is:
Imagine a small bike shop commissioning a new supply management software. Shop’s employees need to check the supplies information to perform their daily job; however, the owner is worried that they might edit supplier orders or other critical information. When developing the software, we basically:
In this way, the feature delivered value is strongly aligned with the user’s expected value during development. The gap between the delivered and the users expected value is generally small, deterministic and controllable.
By contrast, this is not true when developing AI-based products. This is a tradeoff that comes with AI technologies: on one hand it enables features previously unthinkable, on the other hand the delivered-expected value gap presents a larger variance and a less controllable behavior. This is not a negative aspect by itself, but a trait we need to take into account and control.
Teams around the world are building great and flashy GenAI-based demos. At the beginning, the excitement is high, the budget is large, and the stakeholders happily move projects forward. In the Proof of Concept (PoC), the features work well, and the GenAI provides value that is positively perceived by both the team and users.
Then, we scale the PoC both in terms of new features and instance usage, eventually ending up in a kind of purgatory that, unlike traditional software, is particularly difficult to escape.
As the product scales, hallucinations and edge cases occur much more frequently. New features introduce new hallucinations. Old features surface new hallucinations simply because the product is more used. Consequentially, the project excitement is lowering compared to the initial demos.
Iterating is not as easy as a traditional application:
With traditional software, things start quietly, and the energy builds as the product scales. But with GenAI apps, it's often the opposite—the PoC is the high point, and excitement tends to fade afterward, sometimes halting the project before it goes live.
The consequences of these challenges are crucial: the alignment between delivered feature value and user expectations deteriorates progressively. AI-driven features widen the gap between delivered and expected value, which is now less predictable and under control. Why does this happen?
The alignment between delivered and expected value can be negotiable. For example, if a large factory commissions a high-performance Machine Learning Computer Vision system to detect product defects, it's known and expected that the system will have a certain percentage of confidence. They might request a 90%-95% success rate, expecting the rest to be failures (false positives or false negatives). The real alignment issue is not only a technological matter, but it is a combination of the target audience (different requirements and expectations). We are now integrating AI technology for end-users who still have traditional software expectations. Here is where the alignment between delivered and expected value deteriorates.
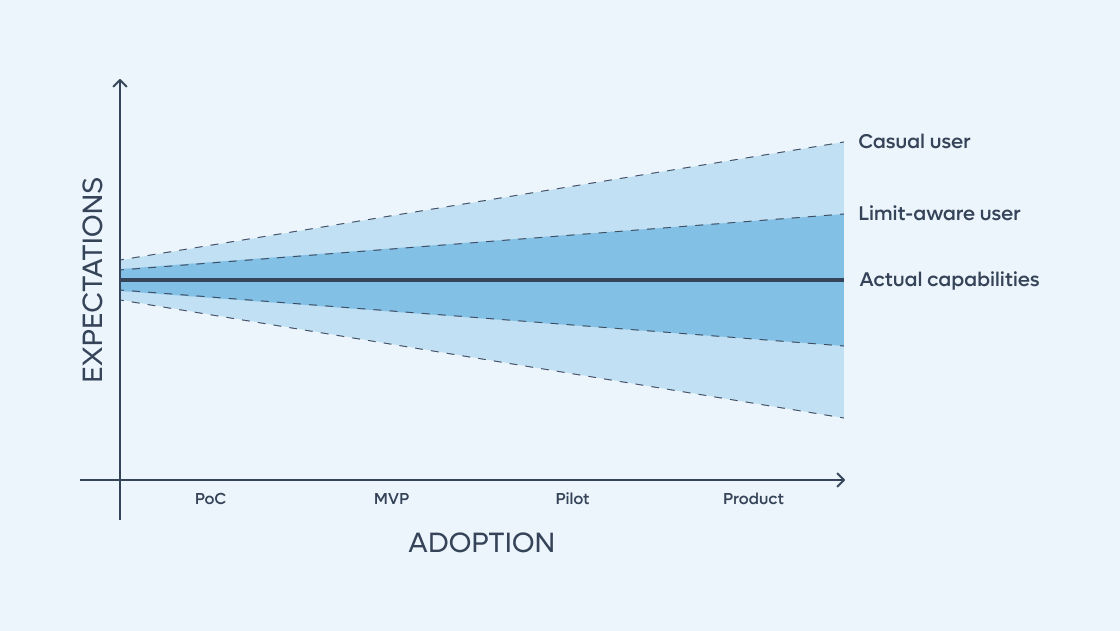
We have just seen that scaling a GenAI PoC into a product presents distinct challenges, unlike those faced with traditional apps.
Most of these challenges come from the generative task performed by the LLMs. It is relevant to note that this is not peculiar of the LLM technology, but rather of the generative task. In fact we would encounter the same challenges if the generative task were performed by a different technology (eg. a pseudo-random string generator). Similarly, we would not have those challenges if we were to use LLMs for a different type of task, for example, a classification task where the target co-domain is limited and statically known.
Therefore, the LLM generative task main challenges are associated to:
In Buildo, we internally look how vertical AI development lifecycle differs from the more traditional engineering one. In the former, the challenges described before are addressed using reliable frameworks.
The real issue is that GenAI was initially approached using conventional practices when it abruptly entered traditional engineering teams. By looking at how professionals develop vertical AI, we can find better ways to solve these mutual challenges. Their SDLC doesn’t feel like a purgatory.
These professionals operate as scientists, heavily depending on the scientific method. In fact, they
…and repeat the process.
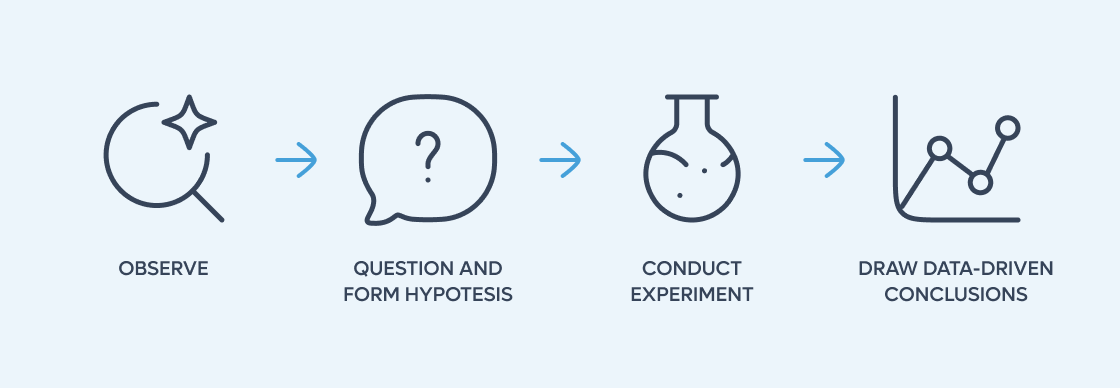
Seems naive right? Yes, but you wouldn’t observe how a read-only accounts feature works, form a hypothesis on the current behavior, design an experiment to validate it, run it, and draw conclusions on the new behavior. You would implement it, and possibly test it, because you already know the expected behavior.
Contrary, in a scientific iteration, you only have a vague idea of the expected behavior. That’s why you question it and form a hypothesis to be evaluated through experimentation. GenAI is no different. We can apply the fundamentals of the scientific method to escape the PoC purgatory. We call this approach, in the GenAI context, Evaluation Driven Development.
Let’s assume we have already developed a strong PoC:
In the following paragraphs, we will walk you through the step-by-step process of establishing a structured EDD process. When developing AI projects in Buildo, EDD is our first choice. We will see it in action on a project we are developing in the financial domain: a multi-agent Chat Assistant.
As prerequisites, we assume that common project goals and targets are already in place: personas, scenarios, definitions of success, and measurement criteria have all been established—just as they would be in a traditional software project.
The first thing we need to worry about is data. Initially, we should gather as much organic data as possible to run our model against real-world use cases. For example, in the case of an AI chat assistant, this means collecting real human questions and replies.
This task could be costly and time-consuming. In the B2C space, it can be hard to get in touch with end-users and gather effective data. While in the B2B space, stakeholders probably intermediate end-users, creating biases. Also, they might not always be available. These issues are strongly misaligned with the initial needs of the project, specifically the need to iterate quickly to validate the product.
For these reasons, generating data is the most effective approach. The goal here is to gather sufficient data to run use cases and validate existing features. Synthetic data should reflect real-world use cases as closely as possible; generation should be based on organic data when available. An even better alternative is to include a Subject Matter Expert (SME) in the process, either to generate or validate synthetic entries. Involving domain experts in the scenarios we aim to simulate consistently adds value.
In our AI Assistant project, data is users’ textual questions to financial professionals. Firstly, we gathered organic samples from real emails provided by the SMEs. Then, the team manually wrote others, trying to navigate the project’s financial domain. Finally, we generated the most significant part of the dataset entries using ChatGPT, with domain-focused prompts. Unfortunately, we couldn’t systematically include an SME in the project in the initial phase. As a consequence, the dataset initially had biases and slight variance, as expected.
Note that here we are still focusing on data to run the model against, i.e. user queries, as opposed to data validating the model output, i.e. assistant responses.

We are now able to run our LLM-based application on a multitude of cases (either synthetic or organic) to see how the features behave. We need to iterate, analyze the app behavior, and provide feedback on the changes based on our insights.
Here is where the glorified “Look At Your Data” slogan comes in. Changes to the application must be based on objective insights derived from the analyzed data. This means that:
So we correspondingly need to
Observability, i.e. logging and monitoring, is the foundation of our feedback loop. The earlier we set it up, the better. There are plenty of observability tools that instrument your application in just a few lines of code, provide cloud storage, and have a nice UI dashboard.
Once in place, we look at our data, make changes, and repeat. At the beginning, we want to focus only on prompt engineering, leaving behind other aspects such as model choice or fine-tuning. Prompt engineering significantly impacts product effectiveness with minimal effort, while other changes refine product quality at a greater cost. It's a classic case of the Pareto rule in action.
At Buildo, we used Logfire to instrument our AI Assistant in just a matter of minutes. While evaluating, we inspect the LLM traces ad rapidly see how local changes affect the output. Moreover, we segregated our multi-agent system evaluation to focus on running and analyzing test cases for a specific agent at a time. Lastly, when opening a PR, a GitHub Actions pipeline runs all evaluation cases so the reviewers can see how the proposed code changes affect the Assistant's end-to-end behavior.
Differently from unit or integration tests, running evaluation tests now has a direct cost in terms of money and time. While it shouldn’t be a priority for the success of the project, it might heavily affect a portion of the budget. In this case, low-effort interventions can make a difference. For example, we set up the pipeline evaluation job to be run manually through a specific (/evals <agent_name>) PR comment, instead of triggering based on git events such as new commits. In our case, this avoided automatically running expensive tests for each fine-grained commit pushed to a PR branch, which is a common pattern in our development workflow.
At this point, we have established an iteration process to efficiently make changes based on our data-driven insights.
However, how do we know those insights are correct? What do we really know about the problem?
Remembering the “Draw data-driven conclusions” task of the scientific approach, it is essential to stress the fact that it is conducted by people expert in their field. The experiment task can be run by different people, but the conclusions drawn are those of the study owner (the scientists).
To make a comparison, we engineers are running experiments and drawing conclusions on a domain we are probably not experts in. The point here is that we can draw conclusions and make changes, but how can we be sure to be on track and aiming in the right direction?
We must employ an aiming target during iterations. We currently have a dataset composed of queries (organic or synthetic) and actual answers of the current model (baseline). We now add a new column: expected answers. These are ideal, high-quality responses to the queries that our LLM-based application should aim for in the long term. We name this version of the dataset Ground Truth: the North Star for our project. Changes must be guided and justified by the content of Ground Truth.
This doesn’t mean the Ground Truth must be a static, unmoved reference for the entire project. As any other part of our application, it needs changes and updates as we validate the features or add new ones. It should be a reference within the iteration loop, and its content can and should be updated in the iteration itself.
Gathering the expected answers has the same issues as gathering the queries: a lack of sufficient data, too little variance, and being expensive and slow. Likewise, we can use synthetic data, but this time the goal is to have high-quality entries for the long term as opposed to having entries to start off working on a large variety of use cases.
For this reason, when building the Ground Truth, involving domain Subject Matter Experts (SMEs) is mandatory. They can either help us to create the expected answers from scratch (more expensive, but faster) or validate our human or generated proposals (cheaper, but requires more iterations).
Having the Ground Truth is essential: the earlier we implement it, the better, because it allows us to iterate on use cases that closely resemble real ones. The trade-off consists of the cost of involving the SME, both in terms of budget and time.
In our project at Buildo, we first gathered organic expected answers from real emails provided by the SMEs, but they were too scarse: we were aiming for a ground truth of around 100 entries, while only a few emails were provided. Similarly to the queries generation, the team manually wrote new samples and used ChatGPT for the rest. But this time, we validated all the samples in collaboration with SMEs, iterating over their content and format. We began this task as early as possible, while developing the agent’s features, so that we could iterate effectively on valuable data once the PoC started to take off.

The process and components we've outlined come together to form the Evaluation Harness:
Remember that the Evaluation Harness must have its own feedback loop. The product and the Eval Harness can grow independently; however, new findings and improvements in one feedback loop probably affect (positively) the other.
Similarly, at what happens with product iterations, the Eval Harness feedback loops can range from the internal team to the end users, with intermediate steps the stakeholders and SMEs. Typically, the closer, the cheaper and less effective the iteration is. The farther away it is from the internal team, the more effective and expensive it becomes.

Trading off iteration ranges and frequency is what makes the best out of the product, by balancing project budget and product quality.
Below is an overview of how we implemented the process for the previously described project use case. Click the image to enlarge.

Engineering teams that are developing LLM-based PoC into products should remember that:

Matteo is a product-minded Software Engineer. He thrives on bootstrapping and scaling digital products, seamlessly integrating AI into software engineering. He cares about business impacts and UX/UI while keenly nerding on software architectures.



Stai cercando un partner affidabile per sviluppare la tua soluzione software su misura? Ci piacerebbe sapere di più sul tuo progetto.

Buildo S.r.l. è certificata ISO 9001:2015 (Sistema di Gestione Qualità) da PJR per la Progettazione e Sviluppo di Software.




