

LLMs default to React, Next.js, and TypeScript, not because they're the best choice, but because they dominate the training data. We explore how this feedback loop impacts innovation, and whether new tech stacks can still break through.
Ask any LLM to scaffold a new web project. The answer is almost always the same: React, Next.js, Tailwind, TypeScript. Not because it's the best choice for every problem, but because it's what the model has seen the most.
This isn't a coincidence. It's a structural consequence of how large language models work. They are trained on the past, and the past is dominated by a few popular technologies. The result is a feedback loop in which the most popular tech stacks are recommended more, generate more code, produce more training data, and become even more dominant in the next generation of models.
But is this really killing innovation? Or could AI actually make it easier for new technologies to emerge? We dove into the most interesting perspectives from across the industry to find out.
Paul Kinlan's Dead Framework Theory makes the strongest case for concern. His thesis is simple and striking: React isn't competing with other frameworks anymore: it has become the platform.
The mechanism is a double feedback loop. First: React dominates the existing web, LLMs train on the existing web, LLMs output React by default, new sites use React, and there's even more React for future training. Second: developer tools like Replit, Bolt, and similar products don't just passively reflect this: they hardcode React into their system prompts because that's what developers expect and can maintain.
Kinlan backs this up with data. According to BuiltWith, over 13 million sites were deployed with React in the 12 months prior to his analysis, compared to roughly 2 million for Vue and under 100,000 for Angular. The Stack Overflow Developer Survey 2025 paints a similar picture: React at 44.7% developer usage, Angular at 18.2%, Vue at 17.6%, Svelte at 7.2%. Token consumption on OpenRouter for programming tasks shows massive growth curves that closely track React's deployment growth. Correlation isn't causation, but the timing is striking.

The implication is sobering: if you launch a new framework today, even one that's technically superior, you need to get into LLM training data (12-18 month lag), convince tool creators to modify system prompts, build a library ecosystem, and overcome developer inertia, all while the existing ecosystem generates millions more React sites.
Maximilian Schwarzmüller makes a related but distinct point: before LLMs, a Google search for "how to build a web app" would surface multiple approaches: different frameworks, different architectures, different trade-offs. With an LLM, you get a single large code block using the default stack. Discovering alternatives now requires the developer to already know they exist and explicitly ask for them.

A recent empirical study by Amplifying.ai puts hard numbers on the problem. They pointed Claude Code at real repos 2,430 times with open-ended prompts (no tool names, no hints) and tracked what it chose. The results are striking: GitHub Actions at 94%, shadcn/ui at 90%, Vercel at 100% for JS projects. The default stack that emerges is remarkably narrow: Vercel, PostgreSQL, Drizzle, Tailwind, shadcn/ui, Vitest, pnpm. Meanwhile, established tools like Redux, Express, and Jest are barely picked at all. Interestingly, the study also reveals a "recency gradient": newer models shift toward newer tools (Prisma drops from 79% on Sonnet 4.5 to 0% on Opus 4.6, replaced by Drizzle). The bias isn't static; it moves, but it remains confined to a narrow corridor.
Not everyone sees a dystopian future. Magnus Madsen, lead developer of the Flix programming language, ran a fascinating experiment: can Claude Code write idiomatic Flix (a language with very little training data) if you give it the documentation?
The answer was surprisingly positive. By downloading the Flix API reference and documentation into the project and providing a CLAUDE.md file with instructions, Claude was able to plan and implement a complete Tic-Tac-Toe game using Flix's advanced effect system, custom handlers, and functional data structures. The model even figured out how to work with NonDet effects on its own.
This points to a powerful counter-narrative: LLMs don't need to be pre-trained on your technology to use it. The real barrier for new language adoption has always been the "cold start" problem: no libraries, no community, no Stack Overflow answers. Today, you can feed documentation to a model and get a working ecosystem in minutes. New technologies have never been so easy to experiment with if you know how to set up the context.
Simon Willison, one of the most respected voices in the developer tooling space, reached a similar conclusion just days ago. He notes that with the latest models and coding agents, the "boring technology" concern doesn't hold up in practice: you can drop an agent into any codebase (even one using libraries too new or too private to be in the training data) and it works just fine. The agent consults existing examples, understands patterns, and then iterates and tests its own output. Willison expected coding agents to be the ultimate embodiment of the "Choose Boring Technology" approach, but his experience suggests otherwise.
Paul Kinlan raised a thought-provoking question back in October 2024, in Will We Care About Frameworks in the Future? While watching AI-generated code in Replit, he noticed something interesting: the code was vanilla. No frameworks, no shared logic, lots of repetition, and it didn't matter, because the AI could refactor anything on demand.
Frameworks exist because humans need ergonomic abstractions to manage complexity. We need patterns, conventions, and structure to not go insane. But an LLM doesn't care about code duplication. It doesn't need syntactic sugar. It can manage tens of thousands of lines of vanilla, hyper-optimized code without breaking a sweat.
Seth Webster, executive director of the React Foundation, takes this further: he argues we're entering a "post-frontend-framework world" where the AI generates React and nobody cares what it generates. The real problem, he says, is that models are trained on the worst publicly available React code, cramming business logic into components instead of building proper service layers.
This raises a provocative question: will we see the emergence of frameworks designed not for Developer Experience (DX) but for Agent Experience (AX)? Tools that are ultra-dense, computationally efficient, and optimized for LLM-to-LLM communication rather than human readability?
There's a darker side to this story. The 2023 paper The Curse of Recursion by Shumailov et al., demonstrated a phenomenon called Model Collapse: when models are trained on their own generated output, the tails of the original distribution disappear. Minority patterns, niche approaches, and less common solutions get progressively erased.
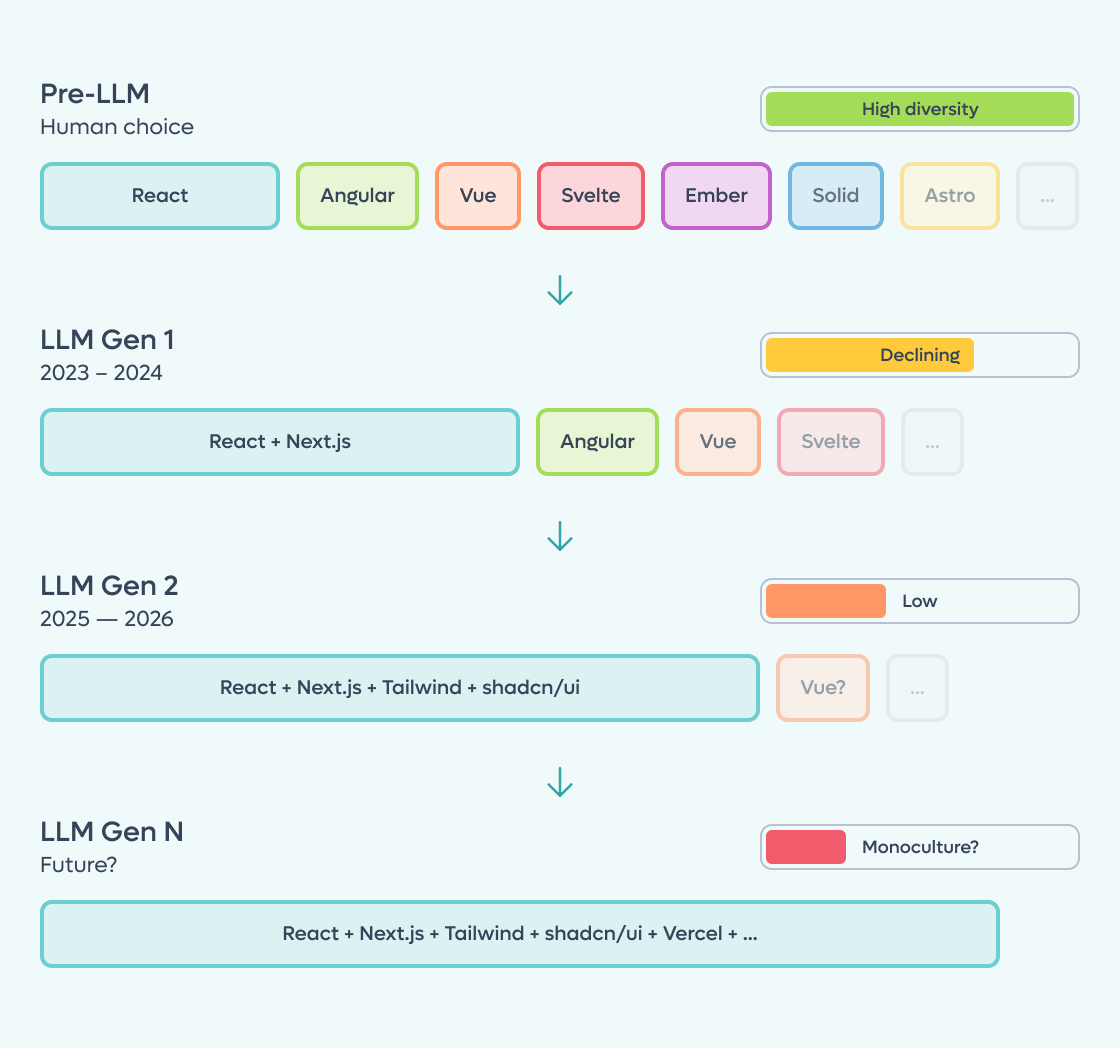
Apply this to code, and the picture gets troubling. If LLMs generate most new code, and that code overwhelmingly follows the same patterns, and then future models are trained on that code, we end up in a narrowing spiral where the diversity of the software ecosystem shrinks with each generation.
The practical consequences are already visible. According to a Pixelmojo analysis, GitClear's study of 153 million lines of code found that refactoring dropped from 25% of changed lines in 2021 to under 10% by 2024, while code duplication increased roughly fourfold. Apiiro's research on Fortune 50 enterprises documented a tenfold increase in monthly security vulnerabilities between December 2024 and June 2025.
The emerging term for this is "code slop": technically functional but semantically hollow code that no longer reflects real-world business logic. Variable names become generic, domain concepts blur, and the codebase loses the intentional design that makes software maintainable.
Projecting these trends forward, a few scenarios emerge:
For 80% of standard applications (dashboards, CRUDs, internal tools), technological innovation may effectively stall. React, Node.js, Python, and a handful of other technologies become the assembly language of the future: a base layer maintained by AI, rarely questioned, rarely replaced.
For mission-critical and novel domains, the story may be different. AI removes the human learning bottleneck. New architectural patterns that previously took years to propagate can now be adopted by teams in days, if someone knows to look for them. This creates a premium on system architects who can think beyond the default stack.
And potentially, a new class of "AI-native" technologies may emerge: frameworks, protocols, and patterns designed from the ground up not for human comfort but for agent efficiency. The shift from DX to AX may be the most significant architectural transition of the next decade.
The tension is real and it's not going away. LLMs have a built-in bias toward the status quo, and that bias creates a powerful gravitational pull toward technological homogeneity. The feedback loop between training data, tool defaults, and developer behavior is self-reinforcing and hard to break.
But the picture is more nuanced than "innovation is dead." The same AI that defaults to React can also learn Flix in an afternoon given the right documentation. The same models that generate code slop can be steered toward thoughtful architecture with proper engineering practices.
At Buildo, we think about this every day. We believe that code generation is rapidly becoming a commodity: the easy part of software engineering. What remains hard, and increasingly valuable, is the ability to design systems that actually work: choosing the right architecture, maintaining quality at scale, and knowing when the default stack is the wrong answer.
The question isn't whether AI will write our code. It already does. The question is whether we'll let it make our architectural decisions too, or whether we'll stay in the driver's seat, using AI as a powerful tool while keeping the critical thinking firmly in human hands.

I transitioned from a full-stack software engineer to focusing on DevOps. I'm passionate about using Vim and k9s in the terminal and have diverse experience in software development and optimizing DevOps processes. Driven by my enthusiasm for technology, I'm always seeking new challenges and innovative solutions to enhance project efficiency and reliability.



Are you searching for a reliable partner to develop your tailor-made software solution? We'd love to chat with you and learn more about your project.

Buildo S.r.l. è certificata ISO 9001:2015 (Sistema di Gestione Qualità) da PJR per la Progettazione e Sviluppo di Software.




